Playing Optimal Heads-Up Poker with Reinforcement Learning
Adopting the Proximal Policy Optimization and Reinforce Monte Carlo Algorithms to Play Optimal Heads-Up Poker
Reinforcement learning has been at the center of many AI breakthroughs in recent years. The opportunity for algorithms to learn without the onerous constraints of data collection presents huge opportunities for key advancements. Google’s DeepMind has been at the center of Reinforcement Learning, featuring breakthroughs with projects that garnered national attention like AlphaZero, a self-trained competitive agent that became the best Go player in the world in a span of 4 days.¹
Traditional reinforcement learning algorithms such as Q-learning, SARSA, etc. work well in contained single agent environments, where they are able to continually explore until they find an optimal strategy. However, a key assumption of these algorithms is a stationary environment, meaning the transition probabilities and other factors remain unchanged episode to episode. When agents are trained against each other, such as in the case of poker, this assumption is impossible as both agents strategies are continually evolving leading to a dynamic environment. Furthermore, the algorithms above are deterministic in nature meaning that one action will always be considered optimal as compared to another action given a state.
Deterministic policies, however, do not hold for everyday life or poker. For example, when given an opportunity in poker, a player can bluff, meaning they represent better cards than they actually have by putting in an oversized bet meant to scare the other players into folding. However, if a player bluffs every time the opponents would recognize such a strategy and easily bankrupt the player. This leads to another class of algorithms called policy gradient algorithms which output a stochastic optimal policy that can then be sampled from.
Still, a large problem with traditional policy gradient methods is a lack of convergence due to dynamic environments as well as relatively low data efficiency. Luckily, numerous algorithms have come out in recent years that provide for a competitive self play environment that leads to optimal or near-optimal strategy such as Proximal Policy Optimization (PPO) published by OpenAI in 2017.² The uniqueness of PPO stems from the objective function which clips the probability ratio from the previous to the new model, encouraging small policy changes instead of drastic change.
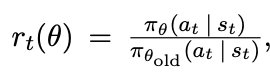
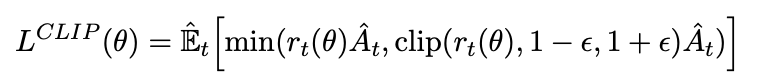
These methods have been applied successfully to numerous multi-player Atari games, so my hypothesis was that they could easily be adapted to heads up poker. In tournament poker the majority of winnings are concentrated in the winners circle, meaning that to make a profit, wins are much more important than simply “cashing” or making some money each time. A large portion of success in heads up poker is the decision to go all in or not, so in this simulation the agent had two options, fold or go all-in.
The rules of poker dictate a “small blind” and a “big blind” to start the betting, meaning that the small blind has to put in a set amount of chips and the big blind has to put in double that amount. Then cards are dealt and the players bet. The only parameters the agents were given were the following: what percentage chance they would win the current hand against a random heads up player, whether they were first to bet, and how much they had already bet.
The packages for comparing winners as well as simulations to determine the percentage likelihood of winning the hand given a players cards can all be found on my Github here. In order to judge the effectiveness of PPO, I decided to compare the performance to that of the Reinforce algorithm a traditional policy gradient method. I chose to test the agents at different big blind levels as well which I set to be 1/50 of their total chips, 1/20 of their total, 1/10, 1/4 and 1/2. After each hand, their chip count was reset and the episode was run again. I ran each through a million simulations and then compared. What was extremely interesting to me was that at no level of blinds, did the difference as measured in chips won between the reinforce and the PPO algorithms become significant at a .05 level. However, the policies of the two different algorithms were extremely different. For example, here is a heatmap of the PPO policy for unsuited cards when the blinds are 1/20 of the stack as compared to the reinforce policy in the exact same scenario.
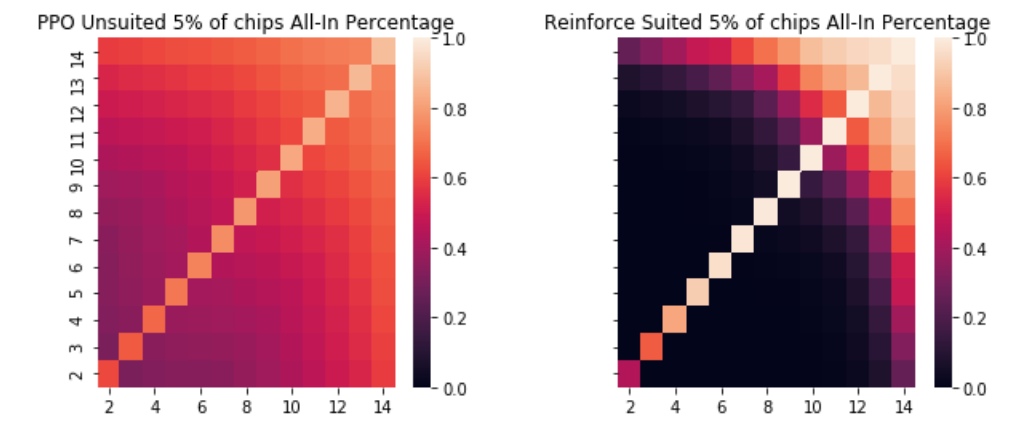
Reinforce is practically a deterministic policy whereas PPO is a far gentler transition meaning that PPO will bluff more while Reinforce will play only with a likely winner. Interestingly enough, these correspond to two different types of poker players. Those that are called “tight” only play when they think they have favorable odds, whereas “loose” players will play lots of hands, bluff and even fold some large hands if they think they are beaten. As the size of the hands increases, the reinforce agent still has closer to a deterministic policy but increases the number of combinations they will bet all-in on.
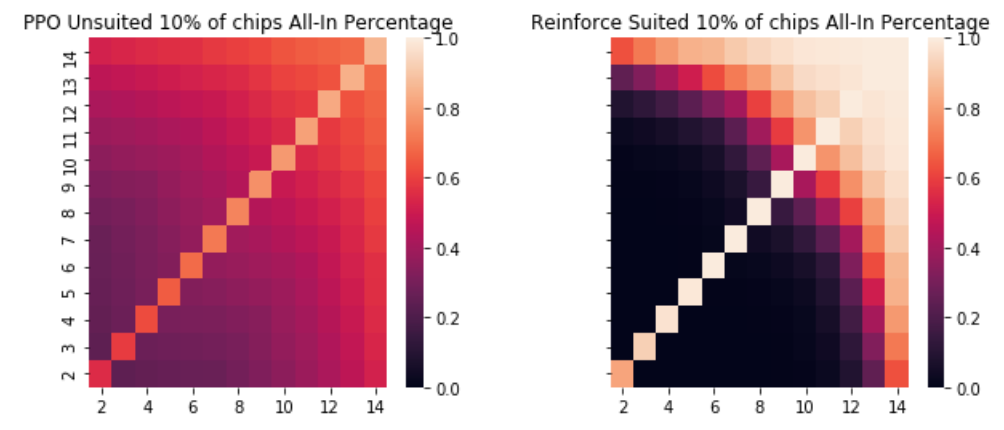
This can be seen as the agent learning a key strategy in poker known as pot odds. This is the concept that as the number of chips you can win increases relative to the size of your next bet you should be willing to play more hands. The reason being that the expected value will allow a lower probability of winning as long as the pot size is relatively large. For example, if the pot is $800 and the bet for you to go all in is $200, you would only need a 20% chance of winning that hand in order to break even in the long run if you bet as you would win $1000 chips 20% of the time thus equaling your bet of 200. However, if the pot is $200 and your all-in bet is $200 you would need a 50% of winning that hand. The agents recognize this aspect and play more loosely with their chips as they are getting pot odds than they had when the blinds were lower. We can see this reach a breaking point when the blinds are 50% of each agent's total chips and practically all hands are likely to be played.
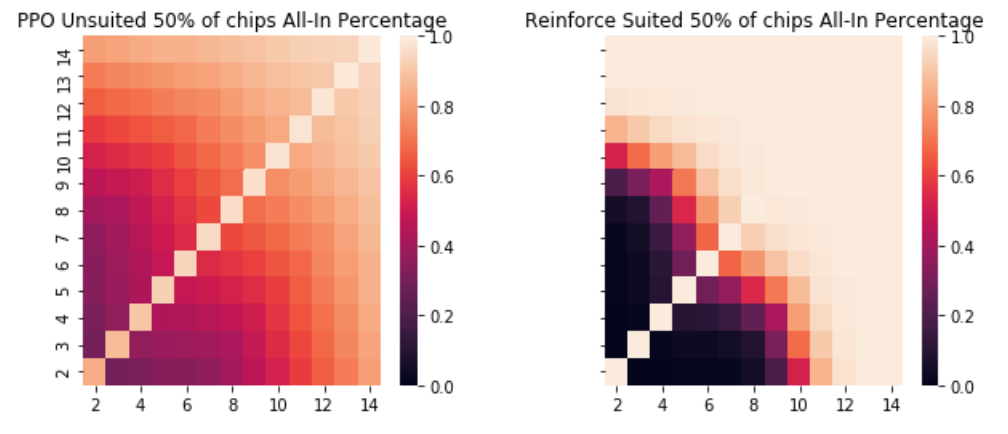
While the agents did not differ significantly in performance, as you can see from the graphs they had extremely different playing styles which was an interesting finding. I expect that as the complexity increased PPO would do better as it seems to have a smoother function that could adapt an optimal stochastic policy whereas Reinforce approached a deterministic policy. Poker, especially this limited scenario, is just one of many possible applications of policy gradient theorems that are continually being explored. It is truly a very exciting time for reinforcement learning.
References
- Silver, Hubert, Schrittweiser, Hassabis. AlphaZero: Shedding new light on chess, shogi and go. https://deepmind.com/blog/article/alphazero-shedding-new-light-grand-games-chess-shogi-and-go
- Schulman, Wolski, Dhariwal, Radford, Klimov. Proximal Policy Optimization Algorithms. https://arxiv.org/abs/1710.03748
from Poker

Post a Comment